[기술 면접 준비 - 2일차] Spring Framework && Database
by Green Frog Developer
Spring Framework
Spring을 많이 공부하셨다고 했는데, Spring Framework가 무엇인지 저희에게 설명해 주실 수 있나요?
스프링 프레임워크란 자바를 위한 오픈소스 애플리케이션 프레임워크로서 자바 기반 엔터프라이즈 애플리케이션 개발을 위해 다양한 서비스를 제공해주는 프레임워크입니다.
Spring Framework의 특징은 무엇인가요?
Spring Framework에는 여러 가지 특징이 존재하지만 대표적인 특징을 뽑자면 IoC, AOP, PSA라고 할 수 있습니다.
IoC란 Inversion of Control의 줄임말으로 개발자가 작성한 프로그램의 제어권이 개발자가 아닌 프레임워크에 넘어가 스프링에서 사용자의 코드를 호출하는 것을 말합니다. 이는 사실 Spring Framework만의 특징은 아니고, 많은 프로그램들이 IoC를 적용하고 있습니다. IoC는 DI와 DL에 의해 구현되는데 DI는 클래스 및 계층간에 필요한 의존관계를 빈 설정 정보를 바탕으로 IoC Container가 자동으로 연결해주는 것을 의미합니다.
AOP란 Aspect Oriented Programming의 줄임말로 여러 모듈에서 공통적으로 사용하는 기능을 추출하여 핵심 로직에 영향을 끼치지 않게 공통 기능을 끼워 넣는 개발 형태를 의미합니다. AOP의 사용 예로는 로깅, 트랜잭션, 보안 등이 있습니다. (사실 이는 자바의 상속이나 합성을 이용해서 구현할 수 있지만, 프로그래머가 작성하는 클래스간의 결합도가 높아진다는 측면에서 좋지는 않다고 생각합니다.) (컴파일 타임, 로드 타임, 런타임 등에서 AOP를 적용 가능하다고 알고 있습니다.)
PSA란 Portable Service Abstraction의 줄임말로 추상화 계층을 사용해서 특정 기술을 내부에 숨기고 개발자에게 편의성을 제공하며 제공되는 기술을 다른 기술 스택으로 간편하게 바꿀 수 있는 확장성을 갖고 있는 것이 PSA입니다.
그렇다면 IoC Conatiner에 대해서는 알고 있나요?
IoC 컨테이너란 Bean 즉, IoC Container에서 관리하는 객체의 생성과 관계설정, 사용, 제거 등의 전체 라이프 사이클을 관리해주는 작업을 하는 컨테이너를 IoC 컨테이너라고 부릅니다. IoC Container의 대표적인 명세는 BeanFactory인데 요즘은 이를 상속하는 ApplicationContext를 사용하는 추세입니다. ApplicationContext는 Bean Factory의 기능 뿐만 아니라, 메세지 다국화, 이벤트 발행 기능, 리소스 로딩 기능 등의 여러 기능을 명세하고 있습니다.
Spring IoC Container의 Bean 등록 방법에는 무엇이 있는가?
xml 설정파일을 이용해서 Bean 등록, @Annotatation을 통해 Bean 등록하는 방법 등이 존재합니다. 하지만 Annotation 기반의 Bean 등록시에는 Component Scan을 꼭 필요로 하는데요, Component Scan을 직접 등록해 줄 수도 있겠지만 Spring Boot는 Component Scan까지 자동으로 구성해줘, 너무 잘 사용하고 있습니다!!!
Spring Boot 이야기를 하셨는데, Spring Boot와 Spring Framework의 차이점은 무엇인가요?
스프링 부트와 스프링 프레임워크의 가장 큰 차이는 Auto Configuration의 차이인 것 같습니다. 한 예로써 Spring MVC 프로젝트를 Spring Framework 기반으로 구성을 한다면, 컴포넌트 스캔, bean 설정, Dispatcher Servlet 설정, View Resolver, JDBC 설정, 웹 jar 설정 등의 다양한 설정을 해야하지만 이를 Spring Boot 기반으로 구성함으로써 초기 개발 환경 세팅에 걸리는 리소스를 많이 아낄 수 있다고 생각합니다.
스프링 부트 프로젝트를 생성할 시 스프링 부트에서는 내장 서블릿 컨테이너인 톰캣(tomcat)이 자동적으로 설정됩니다.
Web Server vs Web Application Server의 차이를 아시나요?
Web Server는 클라이언트로부터 HTTP 요청을 받아 정적인 컨텐츠인 HTML, image file, css 등을 제공하는 서버를 말합니다. Web Server의 예로는 Apach Server, Nginx 등이 있습니다.
Web Application Server는 DB 조회나 다양한 로직 처리를 요구하는 동적인 컨텐츠를 제공하기 위해 만들어진 Application Server를 말합니다. HTTP를 통해 컴퓨터나 장치에 애플리케이션을 수행해주는 미들웨어입니다. WAS는 Web Container 혹은 Servlet Container라고도 불리며 대표적인 예로는 Tomcat, Jetty 등이 있습니다.
Web Server와 WAS를 분리하는 이유는 자원 이용의 효율성 및 장애 극복, 배포 및 유지보수의 편의성을 위해 분리합니다.
Spring Bean을 주입받는 방법에는 무엇이 있나요?
@Autowired 애노테이션으로 필드에 주입받을 수도 있구요, 생성자를 통해서 주입 받을 수 있고, setter를 통해서 주입 받을 수 있습니다. Bean이 주입 될 때 같은 이름 및 같은 타입의 빈이 존재한다면 @Primary 애노테이션으로 우선순위 설정할 수 있고, @Qulifier 애노테이션으로 Bean 이름을 통해서 주입 받을 수 있고, 해당 타입의 빈을 모두 List를 통해서 주입 받을 수 있습니다.
Database System
데이터베이스를 사용하는 이유는 무엇인가요?
데이터베이스가 등장하기 전에 데이터는 파일 시스템을 이용하여 관리되었습니다. 이로 인해 데이터의 종속성 문제와 무결성 문제가 발생하였으며 이를 해결하기 위한 데이터베이스 시스템이 등장하게 되었습니다.
데이터베이스의 특징은 무엇인가요?
데이터베이스의 특징은 크게 5가지로 나눌 수 있고 이는 데이터의 독립성, 무결성, 보안성, 일관성, 중복 최소화를 의미합니다.
Primary Key, Foreign Key, Entity Relation 모델에 대해서 설명해주세요
Primary Key는 테이블에서 각 Row를 유일하게 구분하는 Column을 의미하구요, Foreign Key는 하나의 테이블에 있는 Column중 다른 테이블의 행(row)을 식별할 수 있는 키를 말한다. Entity Relation은 데이터베이스 설계에서 엔티티간의 관계를 표시해주기 위한 모델을 의미한다.
쿼리 문제
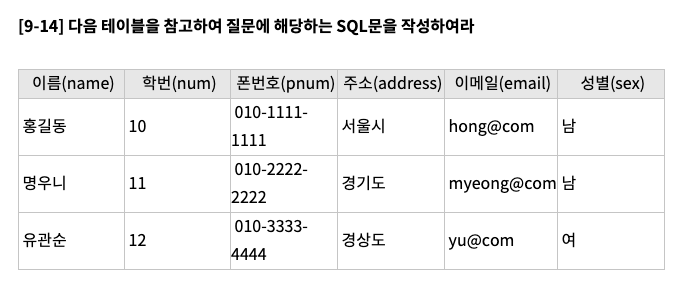
테이블 생성 - 테이블 명은 ‘student’로 할 것
- CREATE TABLE student (name VARCHAR(10) NOT NULL, num INT NOT NULL, pnum VARCHAR(20) NOT NULL, address VARCHAR(10) NOT NULL, email VARCHAR(10) NOT NULL, sec VARCHAR(2) NOT NULL, PRIMARY KEY(num));
테이블 수정 - 대학교(university)를 추가하고 null 값을 허용하게 하라
- ALTER TABLE student ADD university VARCHAR(10) NULL;
데이터 삽입 - 임의의 데이터 2개를 추가하라
- INSERT INTO student (name, num, pnum, address, email, sex) VALUES (“홍길동”, 11, 010-1111-1111, “서울시”, “kim@com”, “여”);
- INSERT INTO student (name, num, pnum, address, email, sex) VALUES (“홍길동”, 11, 010-1111-1111, “서울시”, “kim@com”, “여”);
데이터 수정 - 홍길동의 핸드폰 번호를 010-5555-5555로 변경하라
- UPDATE student SET pnum=”010-5555-5555” WHERE name=”홍길동”;
데이터 검색
- 전체 자료 조회 : SELECT * FROM student;
- 학번이 3번보다 이상인 사람들의 이름과 학번을 조회 : SELECT name, num FROM student WHERE num >= 3 ORDER BY num DESC;
- 김자로 시작하는 학생의 이름을 조회 : SELECT name FROM student WHERE name LIKE ‘김%’;
- ORDER BY xx DESC (내림차순)
- ORDER BY xx ASC (오름차순)
데이터 삭제
- 모든 자료(행) : DELETE FROM students;
- 특정 자료(행) : DELETE FROM students WHERE name=”홍길동”;
Join이란 무엇인가?
Join 이란 2개 이상의 테이블에서 조건에 맞는 데이터를 추출하기 위하여 사용하는 쿼리문입니다.
조인에는 어떠한 종류들이 있는가?
- Inner Join: 2개 이상의 테이블에서 교집합만을 추출
- ex) SELECT A.name, B.age FROM tableA A INNER JOIN tableB B ON A.no_emp = B.no_emp
- Left Join: 2개 이상의 테이블에서 from에 해당하는 부분을 추출
- ex) SELECT A.name, B.age FROM tableA A LEFT JOIN tableB B ON A.no_emp = B.no_emp
- Right Join : 2개 이상의 테이블에서 from과 join하는 테이블에 해당하는 부분을 추출
- ex) SELECT A.name, B.age FROM tableA A RIGHT JOIN tableB B ON A.no_emp = B.no_emp
- Outer Join : 아웃터 조인 또는 풀 조인이라고 불림, 2개 이상의 테이블에서 모든 테이블에 해당하는 부분을 추출
- ex) SELECT A.name, B.age FROM tableA A OUTER JOIN tableB B ON A.no_emp = B.no_emp
인덱스(Index)란 무엇인가요?
데이터베이스의 데이터를 빠르게 검색 및 정렬하기 위해서 인덱스를 두는 방법입니다. (일반적인 책 뒤에 있는 색인을 보는 방법과 비슷합니다.)
DBMS에서 사용하고 잇는 Index 자료구조는 무엇인가요??
대표적으로 B+ Tree 인덱스 알고리즘과, Hash 인덱스 알고리즘이 존재하는 것으로 알고 있습니다. B+ Tree 인덱스는 칼럼의 값을 변형하지 않고, 원래의 값을 이용해 인덱싱하는 알고리즘이고, Hash 인덱스 알고리즘은 칼럼의 값으로 해시 값을 계산해서 인덱싱하는 알고리즘입니다.
Hash란 무엇인가요?
해시란 임의의 길이를 가진 데이터를 고정된 길이를 가진 데이터로 매핑한 값입니다. 이렇게 매핑 하는 함수를 해시 함수라고 하며 이로부터 얻어진 값을 해시 값, 해시 코드, 짧게 말해서 해시라고도 합니다.
해시의 단점은 정렬할 수 없고, 순서에 따라 값을 가져올 수도 없기 때문에 상하관계가 있거나, 순서가 중요한 데이터의 경우 Hash와 어울리지 않는다는 것이 단점입니다. 또한 Hash Function의 의존도가 높고, 공간 효율성이 떨어진다는 점이 단점입니다. 하지만 평균 데이터 처리의 시간복잡도는 O(1)(상수 시간)에 가깝기 때문에 사용하기 빠릅니다.
트랜잭션(Transaction)이란 무엇인가요?
트랜잭션은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다.
트랜잭션(Transaction)의 성질은 무엇인가요?
트랜잭션의 성질은 ACID라고 불리는 원자성(Atomicity), 일관성(Consistency), 독립성(Isolation), 지속성(Durability)이 있습니다.
- 원자성은 트랜잭션의 연산이 데이터베이스에 모두 반영되든지 아니면 전혀 반영되지 않아야 한다라는 것을 의미합니다.
- 일관성은 트랜잭션이 그 실행을 성공적으로 완료된 다음의 상태에서도 데이터베이스느 언제나 일관성 있는 데이터를 보장해야 한다는 것을 의미합니다.
- 독립성은 각각의 트랜잭션은 서로 간섭없이 독립적으로 수행되어야 한다는 것을 의미합니다.
- 지속성은 성공적으로 완료된 트랜잭션의 결과는 영구적으로 데이터베이스에 작업의 결과가 저장되어야 한다는 것을 의미합니다.
정규화는 무엇인가요?
정규화란 데이터베이스에서 중복을 최소화하고 갱신 이상을 없애기 위해 하나의 테이블을 둘 이상으로 분리하는 작업이다. 갱신 이상에는 삽입 이상, 삭제 이상, 수정 이상 등을 포함한다.
정규형에는 무엇이 있는가?
- 1차 정규형: 각 로우마다 컬럼의 값이 1개씩만 있어야 하는 형태를 의미합니다. 이를 컬럼이 원자값(Atomic Value)를 갖는다고 합니다.
- 각 로우의 컬럼이 값이 1개 이상일 경우 1차 정규형을 만족하지 못한다고 할 수 있다.
- 2차 정규형: 주키가 합성키며 부분종속(기본키 중에 특정 컬럼에만 종속된 컬럼)이 없어야 한다는 것입니다. 테이블의 모든 컬럼이 완전 함수적 종속을 만족하는 것입니다.
- 주키가 합성키이며, 기본키 중에서 특정 컬럼에만 종속된 컬럼이 있을 경우 2차 정규형을 만족하지 못한다고 할 수 있다.
- 3차 정규형: 어떠한 비주요 애트리뷰트도 기본키에 대해서 이행적으로 종속되지 않으면 제 3 정규형을 만족한다고 볼 수 있다. 즉, X->Y, Y->Z의 경우에 의해서 추론될 수 있는 X->Z의 종속관계가 없는 경우를 의미한다.
- 일반 컬럼이 다른 일반 컬럼에 종속되는 경우 제 3정규형을 만족하지 못한다고 볼 수 있다.
- BCNF 정규형: 3차 정규형을 만족하면서 모든 결정자가 후보키 집합에 속한 정규형입니다.
- ex) 일반 컬럼이 후보키를 결정하는 경우에 3차 정규형을 만족하면서 BCNF는 만족하지 않는 경우이다. => 테이블 분리가 필요하다.
NoSQL이란 무엇인가요?
관계형 데이터 모델을 지양하며 대량의 분산된 데이터를 저장하고 조회하는데 특화되어있으며 스키마 없이 사용 가능하거나 느슨한 스키마를 제공하는 저장소를 말합니다.
- NoSQL은 SQL보다 덜 제한적인 일관성 모델을 이용하는 데이터의 저장 및 검색을 위한 매커니즘을 제공합니다.
- 단순 검색 및 추가 작업을 위한 매우 최적화된 key-value 저장 공간을 사용합니다.
- 빅데이터 시대에 따라 많은 양의 데이터를 효율적으로 처리하기 위해 등장하였습니다.
- 분산형 구조를 통해 여러 대의 서버에 분산해 저장하고, 분산시에는 데이터를 상호 복제에 특정 서버에 장애가 발생했을 때에도 데이터의 유실이나 서비스 중지가 없는 형태의 구조를 갖고 있습니다.
- HBase, MongoDB 등이 있습니다.
Subscribe via RSS